The Week in Green Software: The Hidden Cost of AI
April 19, 2023

This week host Chris Adams is joined by Asim Hussain and Environment Variables regular Sara Bergman to discuss the hidden costs of generative AI. What’s really at the tip of this iceberg and how far down does it go? They also discuss just how thirsty AI chatbots really are and developments in platform engineering. Finally, we share some opportunities for development from the world of green software.
This week host Chris Adams is joined by Asim Hussain and Environment Variables regular Sara Bergman to discuss the hidden costs of generative AI. What’s really at the tip of this iceberg and how far down does it go? They also discuss just how thirsty AI chatbots really are and developments in platform engineering. Finally, we share some opportunities for development from the world of green software.
Learn more about our people:
- Chris Adams: LinkedIn / GitHub / Website
- Sara Bergman: LinkedIn / Twitter
- Asim Hussain: LinkedIn / Twitter
Find out more about the GSF:
News:
- AI Chatbots Guzzle Enormous Amounts of Water, Study Finds: / Evening Standard [3:16]
- Two-phase cooling will be hit by EPA rules and 3M's exit from PFAS "forever chemicals" / DCD [9:35]
- The Mounting Human and Environmental Costs of Generative AI: / Ars Technica [15:02]
- ChatGPT: Mayor starts legal bid over false bribery claim / BBC [20:29]
- Free Dolly: Introducing the World's First Truly Open Instruction-Tuned LLM / DataBricks [25:19]
- How Platform Engineering Makes Software Sustainable: / Devops.com [30:43]
Resources:
- How much water do data centers use? / David Mytton [8:10]
- Making AI Less “Thirsty”: Uncovering and Addressing the Secret Water Footprint of AI Models / Back Market / UC Riverside & UT Arlington [9:28]
- Jevon’s Paradox / Wikipedia [14:24]
- The AI Iceberg / Ars Technica [22:54]
- Simon Willison’s Blog about Dolly [25:37]
- Breaking the code of silence: what we learned from content moderators at the landmark Berlin summit / Foxglove [28:03]
- Holly Cummins from Red Hat’s Speech at QCon London 2023 [32:34]
{kind=link}
Events:
- Meetup on How to measure energy consumption of software (April 24, Virtual) / Green Coding Berlin [35:11]
- Microsoft India’s Green Software Development Hackathon (March 21 – April 24, 2023 • Virtual): [36:13]
- GreenTech Southwest Meetup (April 20, 6:00 pm - 8:00 pm • Bristol & Virtual): / Green Web Foundation [37:00]
Transcript Below:
Asim Hussain: I'm talking to people in my family, in fact, who are like thinking, will I have a job in two years time? Will I have a job in three years time? And like as historically, we have ignored in the just transition the other side have created a lot of very unpleasant noises, which has forced us to deal with that.
I think the same thing's gonna happen here. I think there's gonna be a lot of noises, and I would love for people to start really talking about how do we make that transition fairer.
Chris Adams: Hello, and welcome to Environment Variables, brought to you by the Green Software Foundation. In each episode, we discuss the latest news and events surrounding green software. On our show, you can expect candid conversations with top experts in their field who have a passion for how to reduce the greenhouse gas emissions of software.
I'm your host, Chris Adams.
Welcome to another episode of The Week in Green Software, where we bring you the latest news and updates from the world of sustainable software development. I'm your host, Chris Adams of the Green Web Foundation. And in this episode we have some interesting news about how thirsty AI chatbots really are, and we uncover the hidden costs of generative AI.
And finally, we share some opportunities for development from the world of green software. Before we dive in though, let me introduce my guests and colleagues for this episode. Today we have Sara.
Sara Bergman: Hi. Glad to be back and in this format as well. So my name is Sara Bergman. I'm a software engineer at Microsoft. I also work with the standards working group here in the Green Software Foundation. I do some conference speaking. I'm actually speaking at conference later this year on this topic in particular. So it's very near and dear to my heart.
Chris Adams: Cool. Thank you, Sara, and Asim.
Asim Hussain: Hi, I'm Asim Hussain. I am the executive director and chairperson of the Green Software Foundation. And I also am director of Green Software at Intel. Excited to be here. Am I supposed to say an anecdote?
Chris Adams: This is when you normally talk about mushrooms Asim.
Asim Hussain: This
Chris Adams: Yeah.
Asim Hussain: I actually bought a robot lawnmower yesterday and it's currently mowing my lawn, so that's a weird anecdote. But anyway.
Chris Adams: That is quite a special anecdote. I don't quite know where to go from there, so I'm just gonna park it and then maybe the,
Asim Hussain: let's cut it out
Chris Adams: yeah, the.
Asim Hussain: robot. It's a really shitty robot. The every few minutes I'm going outside and pulling it out of a ditch. But anyway.
Chris Adams: Okay. And if you're new to me, my name is Chris Adams. I am the executive director of the Green Web Foundation, where we are working towards an entirely fossil free internet by 2030. So before we dive in, there's a reminder. Everything we talk about on this show will be shared as links in the show notes that are published.
So if something did catch your interest, please do follow the link to the podcast.greensoftware.foundation link, and you'll see all the links that we do actually have plus some extra commentary. Let's begin with our roundup of the news then. So this is the first story from the evening standard actually, AI chatbots, guzzle, enormous amounts of water study finds.
So we're starting this episode off with some news from a mainstream news source, the evening standard in London, in the UK. It's actually covering a report from the university of Colorado Riverside and the University of Texas Arlington, where some researchers are working to estimate the water consumption figure for AI chat models such as Google Bard, and ChatGPT.
The water consumption required to train advanced AI models such as Google Bard and ChatGPT is potentially staggering. With training GPT and Microsoft Data Centers requiring something in the region of 700,000 liters of clear freshwater according to our paper from these two universities. The operation used super computers with 10,000 graphics cards and over 285,000 cores.
And this study calls for AI model developers and data center operators to be a bit more transparent about the water usage, as well as suggesting some steps that people could actually do to make better use or incentivize people to use chatbots during cooler, more water efficient hours.
Asim Hussain: Hmm. I think in the parlance of, uh, World. The consumption of water in data is, no one was surprised. No one in the data center space went, oh, water. But it's actually a term, I think, is it? W There's a term called PUE for power. There's a term for water called WUE, am I saying that right? Water Utilization Effect?
Sara Bergman: Yep. Water Usage Effect.
Asim Hussain: And this has come up multiple. This is something I remember when I was at Microsoft. It was one of the, Sara, do they have a target for w I
Sara Bergman: Yeah, for 2030, replenishing more water than they used. But all hyperscalers do have targets for water usage. So it, as you say, it's definitely a known problem in the space.
Chris Adams: This is one of the next ones, so maybe I should ask, Asim. Why do data centers need so much water in the first place? Is it cuz it's when you initially think about it? Yeah.
Asim Hussain: Very thirsty ops People see ops people. They're so big. When the ops people walk around, they just need to guzzle a lot. I think it's for cooling. I think it's for cooling, just cooling service. When you actually look at kind of compute, the challenge of compute is the challenge of cooling and trying to get the maximum from efficiency as possible is all about kind of cooling chips.
So, I'm not sure the mechanism of cooling where it's probably just like typical HVAC systems and things like that, but it's just cooling aspects of it. And I think also from my understanding, it's not just the fact that it's usually, cuz you don't just wanna take put river water in your HVAC system. It's like good quality clean drinking water, which could go to everybody.
But it's also the fact the other end of it, you're pumping out hot water into natural like rivers and stuff like that. And I'm not a hundred percent whether this article or paper covers it, but there's like an impact to nature as well. Some of this stuff, I'm unsure. Maybe both of you have got an idea for this.
Like I'm unsure like why is this, why are we running out of water?
Chris Adams: So in the study there is actually a map mapping out water stress in various regions, and you'll often see overlaps between areas of water stress and data centers typically because data centers as critical infrastructure get to get the first bite of the cherry, as it were, just like with power. Last week, Aerin Booth was talking specifically about this, how when you are considered critical infrastructure, essentially priority goes to storing data about people rather than the people.
That was the phrase he used, which was quite memorable.
Sara Bergman: I think this is a fascinating topic, first and foremost, and also what you can use for cooling is essentially air cooling. So you can like pump in cool air interior data center and use that as a cooling. That works great in some parts of the world for the majority of the year. So where I live in the Nordic this is great. This works great. Other places like Arizona who has a lot of solar power, it does not work so great. Arizona is also water stressed. So you get these multiple climate factors on top of each other, which becomes a problem. And the second part, which makes water very interesting is that it's so incredibly localized.
If we think about our energy grid, that is also localized, but we can send electrons way further with way less waste or loss compared to water. We don't have the infrastructure today to send water over vast amount of stretches of land. We have very localized production of water. There is like even some places in the world where you look at, there are some islands around here in the Nordics, they have like incredible amounts of water facilities because it's just not centralized and cuz there hasn't been a point or they don't have the, a large body of water for which they could centralize, et cetera.
So that makes it an even more localized issue and even more connected to the communities who live in the immediate vicinity of the data center.
Chris Adams: Okay, so this is one of the issues. It's the locality, not just actually the wider thing. There's also a link from here from David Mytton who's a researcher in this field, and he's been one of the people contributing to a number of the Green Software Foundation projects. He's written a bit about how much water do data centers use.
It's really worth looking into because one of the immediate takeaways that you don't really see from this paper is while we are talking about the water used by the data centers themselves, the majority of the water in most cases right now is actually coming from the energy sources, not necessarily the data center themselves.
So you've got water being used to cool, say the generation, like a big fat thermal station, like a coal fire power station, or a nuclear station. So there's a chunk of the water usage there. Then there's the more localized water usage in the data center itself, where it's pulling it out of, say, an aquifer or a like subsurface store of water.
So there's two places to look at, and this is another one of the levers you might actually have. There are tools, as Sara mentioned about different kinds of cooling, like adiabatic cooling, which use ideas from almost hundreds and hundreds of years old, as well as actually the effect at the generation part.
And this is where moving away from burning fossil fuels, I'm gonna keep bringing that in, is a way to reduce the water impact. The paper here actually talks a little bit about having metrics so that you might get an idea of the embedded water in a model, just the same way you might have the embedded carbon in a model, for example.
So it's worth a look, and we'll share a link to the underlying paper as well as the original evening standard piece that was shared. Sara, I spoke a little bit about adiabatic, but you've shared a couple of links which look interesting as well here about the different kinds of cooling available in the world of data centers, which is not really my specialization.
Sara Bergman: I won't say it's my specialization either, but I think it's been some interesting conversations. So this has been a known problem for a long time, which means there have been a lot of people thinking actively about this, which is always a great thing to be in or a great situation to be in. And one of the things that have been experimentally used by several hyperscaler providers is what's called two-phase cooling, which is basically where you use a type of liquid, it's a chemical, not water based.
And then you use this to cool your server acts. It looks wild, but it's apparently very effective. But as of February, this year, the European, oh, let's see if I can find the full name for that. E C H A.
Asim Hussain: Yeah. European Chemical Agency, there's no H there. Where's the h?
Sara Bergman: Where's the chemical? Maybe, I don't know. Yeah. This is how you know we're not chemists in case you tune into the post calls wondering our profession. Yeah, so they, but I think also the American EPA, they both ruled or have concerns about the type of liquid that was used for this cooling, because it's what's called a forever chemical, which we have seen in other areas.
Its not great on, on the environment and the people who inhabit it, but because of that, 3M basically stopped producing these PFAS type of substances, which were used for cooling. And now people are saying that will likely slow down the process of innovation of this two phase cooling.
Asim Hussain: So what I understand about forever chemicals is that these are chemicals that once they're in our bio circle, they'll go into the oceans and the animals will eat them, and then we'll eat them and then we will pee and they'll go in the ocean and it'll carry on going and going. And so all we're eating is like the sludge of chemical and they're all, they're quite damaging.
That's, yeah, that's very scariest. Forever. Forever. Chemicals.
Chris Adams: These are things in like, non-stick frying pans. So every single one of us, we have a little bit of a non-stick frying pan inside us forever now. Thanks guys.
Asim Hussain: looking at my non stick fry pan, probably a lot of non-stick frying pan is inside me right now. The, so, um, Sara, so what I, one thing I've never really. Never really started. One of the questions I've always thought about liquid cooling, cuz I've seen the videos, they look really cool when you've got like a server and it's, it looks like it's boiling water and inside, but it's not.
It's, it's the special oil and chemical. The reason you put servers inside these liquid cooling things is so that you can put more electricity into the server and get more power out of it. So it will make the cooling more efficient. Maybe I'm talking about Jevons paradox type thing, but it'll actually mean there's greater amount of electricity going in. I suppose maybe the trade off is overall better.
Chris Adams: Yeah, these are typically used. You'll see liquid calling and liquid immersion cooling in particular. Is that simply because liquids are much, much more efficient at moving heat than air, right? So this is a really good way to get the heat you don't want somewhere else, and that's a tool that's been used in many cases.
However, it's often quite expensive upfront. A lot of us will usually default to be using air cooling in a lot of places. But yes, as the power density and racks increases, then people are reaching for more kinds of cooling, just like how cars used to be air cooled and now increasing your water cold. You have the same thing happening with increasingly industrial servers.
So yeah, this is something that we could definitely talk about and it's definitely one of the mechanisms that people do use to move some of the heat around. But once you've got that heat, you still need to figure out where it's gonna go and what you're gonna do with it.
Asim Hussain: So just to clear, so with immersion cooling right now, it would allow us to use less water because fundamentally it's more of an efficient mechanism of extracting heat. And so right now it would allow us to reduce the water, but we'll just be back at the same problem in the near future anyway, as the power density increases.
Sara Bergman: Possibly, I'm not sure, but it should also clarify that there are two kinds of liquid cooling so we have the two phase one, which is the forever chemical, and then there is the one phase one which uses a water based or an oil based. And it's, as I understood it, less effective, but it potentially still uses less water.
But yeah, it's always a scale problem, right? Because our industry has to grow. So as we come up with solutions, we outgrow the solutions as well.
Asim Hussain: Yeah. We're in a constant race to, to increase efficiency faster than consumption increases. Yeah. Yeah.
Chris Adams: Outrun Jevon's Paradox,
Asim Hussain: Out outrunning, Jevons Paradox is our challenge. Yeah.
Chris Adams: Okay. And for those who are not initiated, Jevons Paradox is this notion that as things become more efficient, the absolute use tends to increase. This was first noticed when William Stanley Jevons in hundreds of years ago, noticed that making steam engines led to an increase in the use of coal that was being burned because people end up using them in lots of new places.
Just the same way that making cloud can be more efficient. But if it makes more people use cloud, then we still have an increase in absolute usage. So this is one of the things that we are currently wrestling with as an industry basically. Should move on to the next story because it feels like this is a nice segue?
Okay, the next one up is the mounting human and environmental costs of generative AI. This is from Sasha Luccioni, one of the researchers at Hugging Face, but I believe also was working at MLA, a Montreal Institute for Gen. I think she's a colleague of, or was a former colleague of Abhishek, one of the people working in the Green Software Foundation Standards working group actually.
So this one here is a story from Ars Technica and over the last few months, the field of AI has been growing quite rapidly, as we know. And we see all these new waves of new models being used like Dall-E, which is specifically for generating images, or GPT four, which is, you may be familiar with if you've heard of the term ChatGPT every week brings a new promise of new and exciting models, but it's easy to get swept up in the waves of hype. And these capabilities, these shiny capabilities come at a real cost to society and planet. So this piece basically outlines some of the key areas that we need to be aware of. And one of them is actually the environmental toll of mining rare minerals to actually create the GPUs in the first place.
And there's also a bunch here about the training costs increasing over time, how these have been growing larger and larger, and I think the figures we were looking at was actually the economic accessibility of this. So the training cost of GPT three has listed around 5 million dollars, 175 billion parameters, which basically restrict who gets to create these models in the first place. That's the idea behind this. And this also talks a little bit about the climate emissions as well. Citing a study from Professor Emma Strubell, talking about the environmental emissions from an earlier model called Bert, b e r t, which had a figure of around 280 tons of emissions dedicated to the training of this one here.
There's also talking about some of the other larger models and how they're growing over time. So these figures, I think this one refers to things like GPT. The estimated figures would've been if, depending on what the energy source would've been, they were looking at around, assuming you're running this on coal and natural gas, like one of the typical things on the grid, the figures for the actual emissions associated with training are in the region of 500 metric tons of carbon emissions, which is what they've listed here.
Asim Hussain: Yeah, I just think there's a lot of stuff being said about AI. There's a lot of noise. There's a lot of noise about this, and I see a lot of people trying to play down the impacts of AI Both. I'm just gonna talk to sustainability. I think the societal spec, or which I would be happy to talk for hours and end about, but like for instance here, it was just mentioned that just the cost of training GPT-3 was $4.6 million.
That's one training run. How many times have people actually. Train that you tweak it, you run it again, that doesn't uncover inference. And this is also GPT-3, which I believe is an order of magnitude less complicated than GPT-4, which is an order of magnitude less complicated than GPT-5. And when you actually look at the way.
Like the business value of AI models, the emergent properties are coming through vastly more compute and vastly more data. This is just an indication of where we are right now. The future is like this nonlinear curve upwards of even more and more. So I think that's the thing I think to think about and that some of the things people have said to me have been around the lines of, even though it's this big, it's not as big as the airline industry.
It's not as big as other things. Whereas my answer to that is actually one of the reasons why we pay so much attention to software space is so few of us like a 2, 3, 4%, but it's relatively small number of people, the number of people who are involved in training things like GPT is minuscule. The number of people that need to be influenced to reduce those emissions, I think is very small, considering the impact they would have, which is why I would argue it's very worthwhile having strong sustainability conversations in this space. That's my rant on this whole topic. Yeah.
Sara Bergman: I agree. I plus one the rant, but also something that I think is interesting in this space because I really like to read research. And this is a topic that I've been speaking about for a few years now and what I see is there's conversation and research around the training cost and there's quite a lot there and it has been for quite like the paper you mentioned, Chris, that.
From 2019, it's a very well written paper, so I would still argue that people should go and read it. But this has obviously been talked about and I don't know if it's because it's easy to research on or because it's fun, but what I see less obvious inference cost, and when you have these huge production companies, I can only guess that the inference is much higher than the actual training, and any number of times, like a billion is gonna be a big number, but even more in the shadow than inference is data collection, where at least I cannot find any good research on what is the cost of this? How do people do this? And when we have these larger and larger models, well we need larger, larger datasets to feed them. And how do we gather this data and where does it come from? And I don't know, maybe we're awesome at reusing datasets here. I don't really know. But without research, it's hard to say.
So if someone's listening, have a great article, please send it my way. I'd be curious to read it.
Chris Adams: So we'll speak on the labor part for a second, cuz that's definitely one thing that's, that was highlighted in this essay. But Sara, you mentioned something quite interesting about where the data is coming from because there's actually a really interesting scenario that came up literally just this month. If you are using ChatGPT.
Try typing in the name Brian Hood. Ask who is Brian Hood inter ChatGPT right now. Tell me if you get something back.
Asim Hussain: Who is.
Chris Adams: Brian Hood. So b r i a n Hood?
Asim Hussain: It's taken me a long time. I think, mayor?
Chris Adams: Yep. Okay.
Asim Hussain: Okay. An Australian mayor prepares the world's first defamation case against ChatGPT is that what it is?
that what
Chris Adams: Yeah, this is exactly it. So this is a story. Basically, this gentleman in Australia essentially started a lawsuit against ChatGPT, cuz this gentleman was, he was a whistleblower in a significant financial, essentially a FIA financial fiasco back in 2010. And for a long time ChatGPT was basically listing him as the person who was the cause of this.
So, when you have models, which can lie and not tell the right thing, you had this baked into the model. So if you would ask this, it would basically say this person was, it would switch this stuff around. Cause we know that ChatGPT can be a little bit, not entirely truthy, basically, because it's very small auto complete, not actually really intelligence.
And this now brings up the question, how do you actually then retrain the entire model Now to get this person out, you can't just remove the line in a database because the model will break. So there's now a whole set of new research onto retraining and relearning because this person here has a pretty valid request of, Hey, can you please not be defaming me inside this?
There's a human right associated with this, specifically in Europe, for example. This is the kind of things that are currently, we are wrestling with right now. Have to manage either the retraining of this or to allow a sense of redress and accountability. When you are looking at this stuff.
Asim Hussain: Sara are the, well, you are the expert of the AI like cuz we just read that it takes $4.6 million to retrain GPT-3. I presume it doesn't take $4.6 million to edit out this Australian mayor, but it wouldn't be the same as like Google just de-indexing page
Sara Bergman: No.
Asim Hussain: I imagined be significantly higher. Yeah,
Sara Bergman: Yeah, because we have transparency into those systems, right? We don't really have transparency into what makes, yeah, it's like a brain. You don't go in there and just remove a line like, yeah.
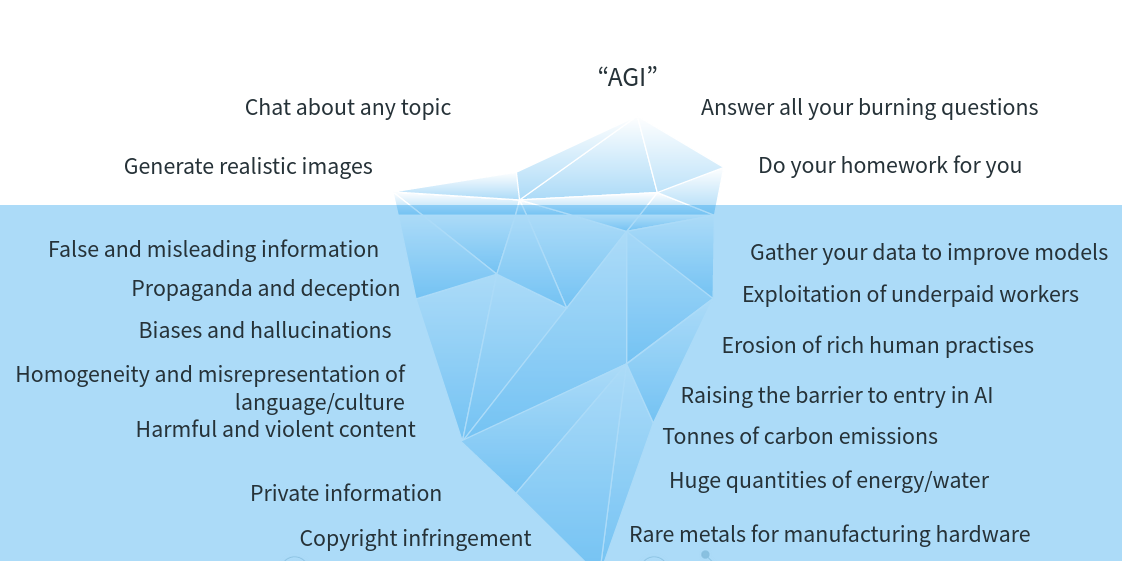
Chris Adams: It's an interesting one to think about that, right? Because if we don't have this, I think the essay does refer to some of these ideas. It presents this idea of a kind of, AI iceberg is the kind of model that's shared inside this with things like the benefits generate really realistic images, do your homework for you, answer questions, and then there's all these other costs and things we need to take- think about like the raising barrier to entry, the actual emissions, the tons of carbon emissions. If it's a 50 tons of CO2 to remove someone's name from a 500 tonne model, then that's quite an expensive refresh cycle when you're developing. If we ever worry about continuous integration, this feels like it's in a different league, for example, that we might need to be somewhat aware of.
Asim Hussain: Or if you wanna delete your data, if you like go with a delete data request, how does it, that has to like factor all the way through. And then the thing is, like we, we've had Anne on. Me and Anne have spoken quite a few times about this idea that really these days it's about developer velocity. Like we have abstracted so many layers.
Like one of the big paradigm shifts in computing was adding like a level of programming abstraction onto hardware, which birthed like an entire explosion of software being written and applications being built because we just made it so much easier to build, arguably inefficient. We weren't focusing on efficiency, we were focusing on speed of developers and speed to getting stuff out to market.
And I'm seeing more and more stuff in the generative AI space, which is a similar idea, which is, it's not really about building efficient stuff, it's just about getting stuff out there as quickly as possible. What if you, instead of writing a really efficient API call, you just wrote like a ChatGPT prompt as an API request, and it gave you like 50,000 words and you stripped 49,000 on the way cuz you needed one. But that was just the quickest way to get a solution. How many times have we built software like that? Have you seen software like that? That's I think the danger of the world that we're heading in is cuz it's all just about that getting a valuable thing out on where does the ef- where our world is about efficiency.
Everything we talk about is about efficiency. So where's the efficiency in this? That's where I'm concerned at.
Sara Bergman: Yeah, no I agree. And I think I called the AI a brain and I already regret it because it is generative, right? It doesn't like, it reads the world and then present it in a slightly different format. I've seen people say, oh, AI has the same biases as us. Like, yeah, because we modeled it after ourselves. At least for now that's how it works. So that's another aspect I think is interesting.
Chris Adams: So this is one thing, we'll just touch on this and then move on to the next story. Have you folks been looking at their new stuff, coming with, I think Databricks published Dolly, which was an open source LLM, and they've also created their first entirely open Creative Commons training dataset. Specifically, they've got a bunch of their own staff to work to create this dataset where there's very clear provenance of where the data's coming in.
So unlike with some tools where you don't know where the data's come from, there's a lot of visibility on this, and there's a chap Simon Willison. He's been blogging all about how he's been able to run these things on his own local machines, but also there are people running these on Raspberry Pi's. Now, they're not very fast, but this is the direction that things are moving to where you see the open sourcing of this.
Because right now, while OpenAI is, we don't actually know where the data is coming from, what data is being used for this, which has all kinds of interesting issues when, like we just mentioned here as well.
Asim Hussain: It's not very open Is.
Chris Adams: We said we were gonna talk about that. There was also one other thing that was touched on here was this, the idea of when you're building an LLM and you're creating this training data, there's also an issue of like hidden labor inside this.
Uh, there are people who are actually paid to be working on this. And I think the piece by Sasha Luccioni refers to actually this time article about essentially Kenyan gig workers being paid less than $2 an hour to essentially examine all the messages for OpenAI. And this is very similar to the kind of content moderation stuff that you see in lots of other places.
I think this is actually really interesting cuz it raises these issues like what do we actually do? Or what can we done to address this issue of like unpaid laborers or underpaid people working in AI model development. Cuz that's not necessarily the people writing the code, but there's definitely people involved in doing that just like we have when other platforms, for example, too,
Asim Hussain: I think this is where things get very interesting with, and I'm gonna stray very far beyond sustainability right now, but we're talking about why are they getting paid so little is because it's unskilled labor, right? It's unskilled labor, and that's why you can get away with paying people $2 an hour.
When the AI is a de-skilling the workforce anyway, right? So the de-skilling the workforce and like I saw somebody post the day, like maybe the future of software developing is just prompting ChatGPT, which is an interesting idea, but I'm thinking like, how much are you gonna pay somebody to enter prompts into ChatGPT versus-
Chris Adams: As a prompt
Asim Hussain: engineer.
As a prompt engineer.
Chris Adams: So there's an issue of underpaid or very low paid labor involved in the AI model development that we don't really have really well addressed right now. And this is something that definitely needs to be addressed. There is actually one thing that may be worth looking at in other fields where you do see this, where you have the use of gig workers involved in this, like content moderation.
There's lots of parallels to this kind of work where you have people who are considered outside of a firm who have to do this work. And typically what we've seen there is actually honestly workers organizing and talking about their, the conditions they need to be part of. There's a link to Foxglove, the UK law firm, who are doing some really interesting work specifically about representing the power and representing essentially people working in these kind of moderation or below the API kind of roles because they are very clearly part of it.
And depending on when you look at the cost structure for a particular, say, organization, like if you look at, say, Facebook for example, Facebook might have made something the region of over a hundred billion of revenue last year. And this project, the actual moderation, which is one of the key parts, there is a single contract to a consulting firm for 500 million dollars for that part there, which is less than half percent of the revenue is being dedicated to this part here.
And that's an issue about, okay. How are you representing these costs when we're creating this and how do we actually make sure that there is a just and a correct way to actually recognize this kind of labor, especially to address some of these issues? Cuz it doesn't seem particularly fair to me right now to do this.
Sara Bergman: And I think it's also interesting because this is not the first time in history this is happening, right? Machines have been taking jobs from humans since the Industrial Revolution, but we want it to be for good. We want the machines. Whether that's a mechanical machine or a digital machine to take away the dangerous, the boring, the damaging jobs so that we as humans can focus on the fun, create a positive things of labor.
And here you have a paradox, right, where this is potentially improving the working conditions of one group of people, but forcing it for another group of people. And how do you represent that and how do we solve that? Yeah.
Asim Hussain: There's a lot of parallels here cuz we're talking about this in the energy transition as well. We're talking about just transition. We're talking about if we wanna move everybody over towards renewables, we have to think about the people that are in other industries because one of the reasons, cause they vote and they'll get quite upset if they lose their jobs and don't have an option.
So it's always been like this thing as towards just transition and I'd love for there to be conversations about that happening right now in the AI space. Cause I'm talking to people in my family in fact who are like thinking, will I have a job in two years time? I'll have a job in three years time. And like as historically, we have ignored in the just transition in the other side have created a lot of very unpleasant.
Which has forced us to deal with that. I think the same thing's gonna happen here. I think there's gonna be a lot of noises, and I would love for people to start really talking about how do we make that transition fairer?
Chris Adams: I think this is one that we need to dive into in a bit more detail in a future one. In the meantime, Foxglove is probably one organization that's doing some really interesting work in this field at the moment, and I believe there is some work coming from AI now in this field as well. Okay, so the next one is, Platform engineering, how platform engineering makes software sustainable.
So this story here comes from devops.com and the kind of thrust of this story is platform engineering seems to be essentially an idea of providing self-service tools for software teams themselves. So they are able to say, spin up an application or access, spin up a database. Ideally in our kind of green software world, spin up a cluster that turns itself off at the end of the day.
Because we do know that one of the big issues we have is that people just leave things on. Cause it's easier in terms of people's time to leave, loads of things running rather than turning them off. So this is the idea that by incorporating tools like Cube Green or some of the metrics tools, uh, I think Spotify had been doing, you can essentially set some more sustainable defaults for teams rather than relying on them to remember to do all this stuff themselves.
That's the general idea for some of this. Those are the benefits. Being proposed was, yeah, less friction. Reduction of cognitive load for developers. Basically consistency across the board. That's one of the things that seems to be pushed in this angle here.
Asim Hussain: Yeah, I'm seeing it's got two aspects to it from a sustainability perspective, and I like the way they phrased it. They're talking about observability and optimization. You know, observability is like, how do you. Having that visibility. Most people don't really know. They don't think we have. I think we should tell 'em that the secret Sara about how people use cloud?
Like most companies haven't got a clue like what's going on. And they're like sending out emails going, why are we spending $50,000 on this thing? And somebody goes, oh, I forgot to switch that off two years ago. That's like a level of visibility which exists right now. And so like any kind of like surfacing of that observability.
And when I was at Microsoft, I got that email like every, two weeks we hired someone just to email everybody, to tell them to switch things off cuz it was costing so much money to keep it running.
Sara Bergman: And actually at QCon in London last month, Holly Cummins from Red Hat, she actually had a whole talk on cloud zombies and she told a lot of these funny stories. So if you had the chance to catch that, she covered a lot of it because yeah, it's harder even with on-prem because then you might have a physical server.
That you don't even know where it's located in your buildings cuz you run a university and you have lots of buildings or whatever. And uh, yeah.
Asim Hussain: I have definitely remember, this is a long time ago and it was not Microsoft. So before you think I'm saying a Microsoft story, I remember. I was doing audits and then discovering machines that hadn't, we just completely forgot about, completely, utterly forgot about whole machines.
Chris Adams: So the company was making so much money that they didn't have to care, or they didn't realize that it
Asim Hussain: You can look through my LinkedIn and probably guess. Yeah.
Sara Bergman: but I think this is also interesting because if we look at data centers. We have seen on-prem data centers that are managed by one corporation for their own sort of benefit. They're typically way less effective than the hyperscaler cloud platforms, and that is because they can spend their money as in engineering resources to make them so efficient, because it's worthwhile the investment for them just in pure monetary cost because that's their primary business, whereas, Company running an On-Prem data center.
It's not their primary use case. They're maybe never gonna have enough people to do asset management in the most effective way possible. And it obviously depends on how you do it, but this internal developer platforms platform engineering situation, it could be the same thing, right? It all depends on how you do it, but potentially if you allocate a small group of people who are responsible and sustainability is one of their primary goals, then they have the incentive to spend the engineering capacity, and I'm saying engineering, but really any kind of practitioner that you are to make it more sustainable instead of having 10 different teams all have to fight for the same change. So it has potential, but it's possible to say the outcome without really getting into the nitty gritty.
Asim Hussain: I loved your explanation there. I'd never really heard it phrased that way, but yes, like Microsoft and Azure, the team, you're making money through Azure, so you're gonna make Azure more efficient. But if you are a consumer, you're making money by selling shoes or something.
Sara Bergman: Yeah.
Asim Hussain: Yeah, that makes a lot of sense.
Yeah.
Chris Adams: Alright let's talk about some of the events that we have listed inside this then. We have just a few meetups and events, which might catch your eyes of some people. These are all virtual events. So the first one is a meetup on measuring the energy consumption of software. This is some work by a group called Green Coding Berlin.
They're a small but mighty little outfit working on some very literally named tools. Like we can probably guess what the Green Metrics tool might do, right? As you can imagine. Does that, and they've got another tool called Eco CI, should we guess what that one does?
Asim Hussain: Continuous. I'm trying to think of something funny for I, but I can't think of anything. Integration.
Chris Adams: So, yeah, this is a small team of Berlin based developers who've been building a bunch of entirely open source tools specifically for this. The thing that I might share with you that might be interesting is that some of this work looks like it's probably gonna be fitting into the work with Wagtail at Jango based CMS on the Google Summer of code that we mentioned last week, where the goal is to actually start figuring out what the environmental impact of running various CI tools actually is, but also to measure where the, where the savings might actually possibly be inside open source tools. So you can pull out some of these patterns cuz we have things like patterns in the Green Software Foundation. Some of those might be applicable specifically for this.
There's a Microsoft Green software development hackathon from the 21st to the 24th of April.
Christ, that's this weekend, isn't it?
Asim Hussain: Oh wow.
Sara Bergman: Yeah.
Asim Hussain: I thought this was like the internal Microsoft Hackathon, but this looks like an external one. It looks like Microsoft India is having a green software development hackathon and Wow. 1,945 registrations, so good luck if you're applying. You've got a lot of stiff stuff. I got a lot of competition there.
I dunno what the prize is, it doesn't say.
Chris Adams: I don't see actually that much in the prizes listed here either, but I'll be honest folks, I dunno about you, but. I'm gonna sound like an old fart now, but like when I first got involved with this, they weren't called hackathons. They were called hack days. With the idea being that you'd like work on something, you're not trying to win a prize, you're doing it because actual hacking on something is interesting in the first place.
You figure out what can actually do rather than to win something to kick off your startup, basically, I. I'm a bit confused about this part, but uh, yeah, it looks like it's happening this weekend. Maybe if something comes out of it, we might feature it.
And then finally there's the Green Tech Southwest Meetup in Bristol of all places.
This one is run by Hannah Smith of the Green Web Foundation, and it's featuring two people. Adam Turner, who's the head of digital sustainability at DEFRA. That's the Department for Environment Food and Rural Affairs, who are the kind of defacto environmental department for the UK government.
Asim Hussain: Thought it was DARPA.
Chris Adams: Oh, not that's, that's America and that's a slightly
Asim Hussain: Oh, is that the me? Okay. Isn't that the weapons one? Any whatever.
Chris Adams: No, that's, yes.
The, there there is DARPA and darpa E. These are the folks. I'm out by death here. I'm not gonna pretend to, to know what DARPA is or what it, or what the significance would be for this one. I'm actually quite excited about this because this guy, Adam has actually been writing quite a lot about where the challenges are, and he's also been talking about, okay, these are the things that we're doing as a government with legally binding targets that we need to be meeting, and this is what our sustainability strategy looks like.
And the nice thing is that. If you are not sure about what to do, because the UK government publishes all their stuff, you can kinda copy their homework to get an idea of what you might apply internally for yourself, and they're actually got a really quite well-developed team and there's a lot of really interesting stuff to be looking at for both just on-prem and in cloud and things like that actually.
Asim Hussain: Mm, very interesting.
Chris Adams: We've spoken about the news and the events. I guess there's a question. We spoke a little bit about this generative AI iceberg and some of the things that should be on this list. Is there anything that isn't there that should be there? Maybe Sara, I might start with you. If there's anything that we should be putting into this AI iceberg as things that people should be aware of that will share a link in the podcast for.
Sara Bergman: Yeah, so one thing that I saw that wasn't there was lack of diversity in research. They said lack of interest. So maybe the same thing, but I think with the increasing cost, if really only the really large universities and or the really big corporation can participate in this sort of bleeding edge AI research, we're missing out on emerging research for people who probably have great ideas and couldn't do this incredibly well, but simply don't have the monetary resources.
Chris Adams: That's a really good point to mention here cuz when you see a lot of these papers, they tend not to be coming from that many different places so far, and this was something that was raised in an earlier discussion, an earlier paper, basically making the argument that, yeah, when you only get models coming from Western Europe and North America, you're probably gonna miss out on a bunch of extra context that we are currently missing.
In the same way that in lots of other places, when you only have modeling from certain parts of the world, you get an incomplete idea of what modeling the world might be looked like or what kind of policy options we do have to meet the climate challenges that face us.
Sara Bergman: Yeah, because talent is equally distributed opportunity's not.
Chris Adams: Indeed.
Asim Hussain: I love that.
Chris Adams: I think we'll leave on that one as a challenge from this. So that's all for this episode of The Week in Green Software. All the resources for this episode and papers and links will be available on the Green Software Foundation podcast website, which is podcast.greensoftware.foundation. So thanks again for listening and we'll see you on the next episode.
Thanks, Sara. Thanks Asim.
Asim Hussain: Thanks, Chris. Thanks. Thanks everyone.
Chris Adams: Bye.
Sara Bergman: Bye.
Chris Adams: Hey everyone. Thanks for listening. Just a reminder to follow Environment Variables on Apple Podcasts, Spotify, Google Podcasts, or wherever you get to your podcasts. And please do leave a rating and review if you like what we're doing. It helps other people discover the show, and of course, we'd love to have more listeners.
To find out more about the Green Software Foundation, please visit greensoftware.foundation. That's greensoftware.foundation In any browser. Thanks again and see you in the next episode.